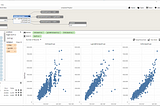
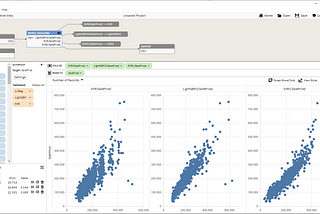
MonumentMonument vs. H2OH2O can get you to a similar end, though it is a much different tool — more similar to Scikit-learn, SparkML, or packages of choice from…Feb 4, 2021Feb 4, 2021
MonumentBuild Your Own COVID Prediction Models In Minutes — Without Writing Any CodeCOVID has dramatically altered all of our lives. The corresponding flurry of information — and sometimes misinformation — has made these…Nov 14, 2020Nov 14, 2020
MonumentMonument Introduces Model Serving CapabilitiesNEW YORK, N.Y. — Monument is pleased to announce the roll out of “model serving” capabilities. Model serving enables users to train…Nov 2, 2020Nov 2, 2020
MonumentBuild A Pricing Engine With No-Code Machine Learning in One AfternoonStop putting prices on things by guessing. You’re leaving money on the table. A great use-case for Machine Learning is building pricing…Sep 14, 2020Sep 14, 2020
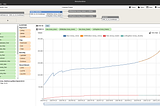
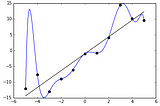
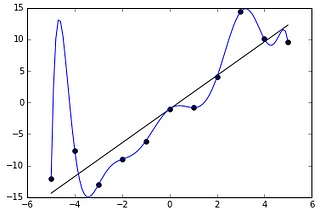
MonumentWhat is overfitting? Why is it bad? And how can I avoid it?Pop quiz. In the above chart of eleven historical datapoints, which of the two lines in the picture above would be the most accurate for…Sep 11, 2020Sep 11, 2020
MonumentTop 5 Reasons Why You Should Use No-Code Tools To Get Started With Data ScienceIt’s easier to get started. Data science does not have to mean months or years of work to get started. With a no-code platform you can go…Aug 26, 2020Aug 26, 2020
MonumentMonument Expands Offerings With Classification AlgorithmsNEW YORK, NY. — The Monument team is pleased to announce the addition of classification and regression methods into our zero-code machine…Aug 25, 2020Aug 25, 2020
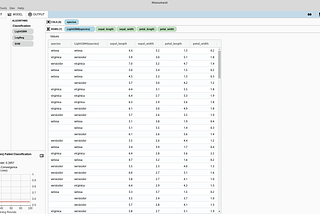
MonumentPredicting Debt Payment Defaults With No-Code Classification AlgorithmsPredicting the likelihood of future events like fraud or payment defaults is a classic use-case of machine learning. With its…Aug 15, 2020Aug 15, 2020
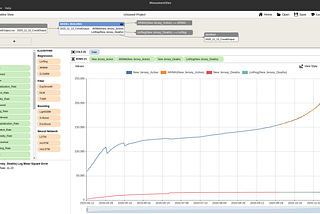
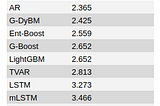
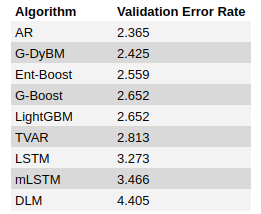
MonumentinThe StartupHow to Decide Between Algorithm Outputs Using the Validation Error RateMonument (www.monument.ai) enables you to quickly apply algorithms to data in a no-code interface. But, after you drag the algorithms onto…Aug 12, 2020Aug 12, 2020
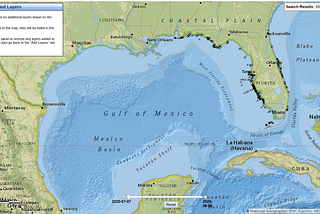
MonumentinThe StartupUsing Open Source Data & Machine Learning to Predict Ocean TemperaturesIn this tutorial, we’re going to show you how to take open source data from the National Oceanic and Atmospheric Administration (NOAA)…Aug 10, 2020Aug 10, 2020